The IT environment is the most important thing we have in an IT organization. It is where IT services are produced and benefit is supplied to the business. If the IT environment was to stop functioning, the IT service would come to a halt and the business would then derive no benefit from the IT organization.
It is with this in mind that the IT organization needs a fast and well-aligned process to restore errors which arise in the IT environment. If an element that the IT organization has promised in agreements with the business is not functioning, then there is nothing more important at that precise moment.
A fundamental prerequisite for the Incident Management process to function is that clear agreements are in place. That there is absolute clarity about what should function and what should not. Otherwise there is a risk of the process becoming clogged with issues that are not directly linked to an error in the IT environment. The IT organization then grows accustomed to a constant flow of incidents with the result that the link to incidents being important disappears.
An incident is defined as:
” An unplanned interruption or a deterioration in the quality of an IT service. An error in a component in the IT environment that does not directly affect the quality of the delivery (for example, a hard drive with redundancy) should also be classified as an incident.”

Purpose
The main purpose of the Incident Management process is to restore the agreed service level as quickly as possible and to reduce the negative consequences for the business. This means that if the IT organization is not able to rectify the error directly, a temporary solution (workaround) which restores the functionality for the user can be sufficient. The purpose also means that an incident should as far as possible be rectified in such a way that the business suffers no further negative effects.
The purpose of Incident Management is achieved through:
- Ensuring that standardized methods and procedures are used
- Making incidents visible internally and in the business
- Acting professionally through communicating and resolving incidents rapidly when they arise
- Starting out from the business’s priorities when prioritizing incidents
Scope
The word incident means ”unexpected, disruptive event”. Incident Management is consequently ”management of unexpected, disruptive events”. This means that expected, disruptive events are not included in the Incident Management process.
To set a clear limit on which disturbances can be expected and which cannot, this is regulated in documentation which is produced in the Release Management process. Errors detected during the testing of releases that are deployed should be documented as known errors. This documentation of known errors is subsequently used as a definition of what is unexpected or expected. This means that if an error registered by a user is recorded in the list of known errors, the issue should not be regarded as an incident. The difference between types of issue and how these are to be managed is described in more detail in the chapter about the Service Desk function.
All incidents in the IT environment, independently of who discovers them, are included in the incident process. All incidents that affect the delivery of IT services, regardless of who produces the service, must be included in the incident process. This means that an error which arises at a supplier, which in turn affects the delivery of IT services, should also be regarded as an incident.
Value for the business
The Incident Management process is usually one of the first and most high-profile processes to be established. The reason is the clear connection between rapid management of errors in the IT environment and the benefit for the business. More specifically, the process contributes:
- The possibility of rapidly tracing and resolving incidents in the IT environment which reduces the effect on the business and contributes to increased productivity for the customer.
- The possibility of prioritizing between various simultaneous errors according to what is the most important for the business contributes to increased productivity in important functions.
- The possibility of identifying opportunities for improvement, for example replacement of old and unstable hardware, can increase productivity for the customer.
Prioritization model
It is beneficial to use a common model to make priorities, regardless of types of issue. It simplifies the task of prioritizing and reduces the risk of misunderstandings when the issues are sent between different parts of the IT organization.
Regardless of issue, the first question is what effect the issue has for the business right now. The question is answered with either high, which means that the business cannot continue if the issues are not managed, medium, which means that the business can continue but with inconvenience or low, which means that the business can continue with no inconvenience.
The question is subsequently posed as to what effect the issue has for the business within the foreseeable future according to the same criteria. The answer to the question is often not the same as the answer to the question of what the effect is right now. For example, an issue which is not time critical right now can cause the business to come to a halt if it is not resolved in one month.
The third parameter is the time frame for future impact. It should be described as a time specification, i.e. the latest date on which work on the issue must be commenced.

The prioritization is subsequently made as an overall assessment of current and future impact.

The priority level is assessed with the emphasis on the present situation. It is therefore important that current and future impact are described textually in the issue so that all issues can be subsequently reprioritized on an ongoing basis as time passes. The time frame can also be used here to flag up reprioritization. This model provides sufficient information to manage reprioritization and also effective data if the issue should be forwarded to another unit inside or outside the IT organization.
Major Incident
The Service Desk function, which primarily manages incidents, is optimized for throughput. Incidents should be resolved as quickly as possible and the administrators in Service Desk should be able to tackle a large number of issues in each shift. There is therefore reason to have a separate procedure for incidents which are of such a size or have such an impact that they require the IT organization’s full attention throughout the incident’s life-cycle. Such incidents are classified as major incidents.
A major incident should have a separate, predefined procedure with faster escalation routes and greater decisiveness. The procedure should have a well-defined trigger which engages the incident process’s prioritization. A separate team to resolve the incident should be convened and include:
- Incident manager
- Problem manager
- Service owner
- Applications Analyst and/or Technical Analyst
- Documenter
- Communications Officer
Even if the solution to the incident is obvious, a problem record should be created in order to prevent the incident reoccurring. The issue should be kept separate throughout the incident’s life-cycle so that there is no risk of it delaying the solution. A major incident must always be concluded with an evaluation of the job so that the procedure is continually improved.
Activities
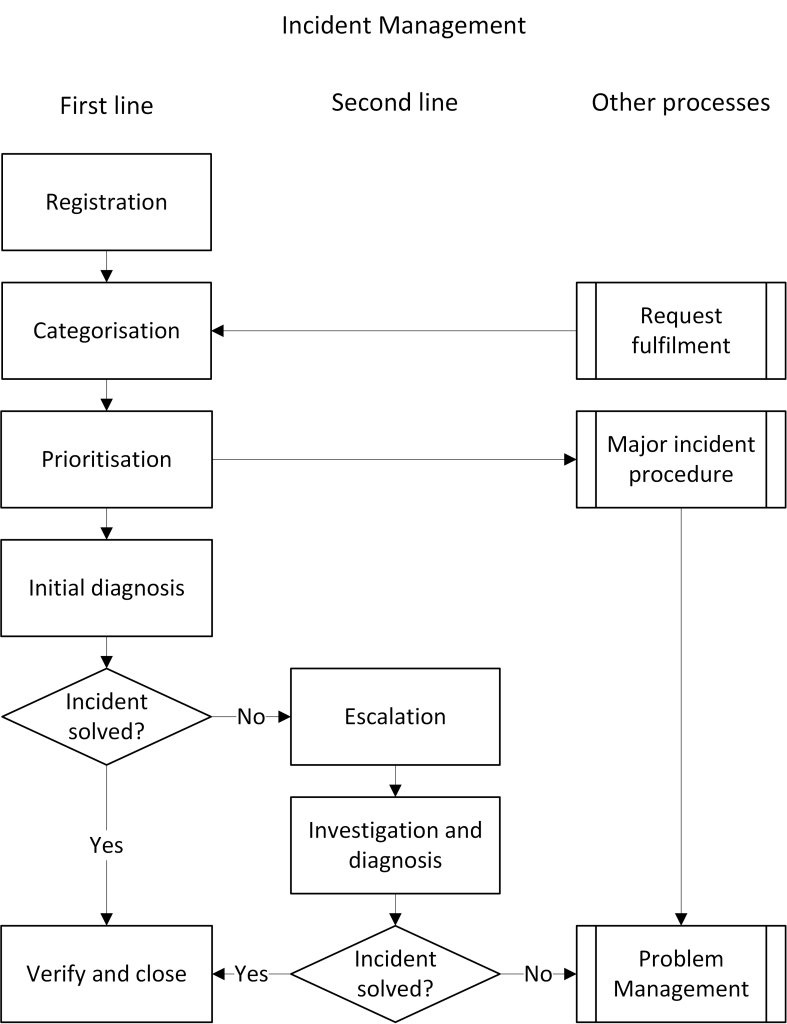
The following activities are part of the Incident Management process. If the issue arrives at Service Desk via a user, the first two activities (registration and categorization) are managed in the Request Fulfilment process.
Registration – All issues must be registered with the concerned user, equipment and a detailed description of the issue. It is usually here that automatically generated incidents end up via an alarm, where administrators can pick them up and supplement the information. If an issue is passed on to another group/organization for further investigation, the work is made considerably easier when full and adequate information is entered in the issue.
Categorization – Categorize the issue according to a predefined list. The categorization is the same regardless of type of issue, and it reflects the service catalogue’s structure in order to facilitate, among other things, responsibility issues and statistics.
Prioritization – The priority is determined through a combination of current impact, future impact and time frame according to the prioritization model.
Initial diagnosis – The service desk analyst tries to resolve the incident immediately using his/her own knowledge or documentation in previously registered incidents, problems and known errors and subsequently closes the issue. If an immediate solution is impossible, the incident should be escalated.
Escalation – Escalation to second line support within Service Desk or an external supplier is called functional escalation. Resolution of an incident might sometimes need more decisiveness; this is called hierarchical escalation. Examples of this can be restart of a common function or a reinstallation which requires permission.
Investigation and diagnosis – Second line support does not usually have the user on the line and can therefore put more time and energy into resolving the incident. The basic rule is that it should be possible to resolve the incident using documentation and personal knowledge, however, a time limit is also usually set, which is linked to the priority for how long the work of error location for an incident may proceed before a problem should be created.
Create a problem record – If second line support is not able to resolve the incident within the given time, a problem record should be created. The incident manager should be involved in order to potentially decide whether to also raise the priority level to major incident.
Verify and close – All solution groups can close an issue after having checked with the user that the function is restored. If a change in the IT environment is required to rectify the incident, the Change Manager should be contacted to implement an urgent change in the IT environment.
Documentation
The following documentation should be in place within the framework of Incident Management:
History of previous incidents containing:
- Date and time
- Name of administrator
- Description of symptom
- Measures
- Incident categories
- Major incident procedure
- Incident types with proposed solution
- Contact details for internal and external solution groups
- Prioritization matrix
- Description of effect on each IT service
Relationships with other processes and functions
The Incident Management process has links to many other processes. The most common are listed here:

Trigger
Incident Management is triggered through:
- A user contacting Service Desk about an error
- A system automatically registering an error
- Someone in the IT department detecting an error
- A supplier contacting the IT organization about an error
Input
The following inputs are needed for Incident Management:
- Documentation of all IT services and their associated components
- Information about known errors and temporary solutions
- Information about previous incidents
- Information about changes implemented in the IT environment
- Agreed service levels for the IT services
- Documented criteria for prioritizing and escalation
Output
The following outputs are generated by Incident Management:
- Resolved incidents
- Updated documentation about activities performed linked to the incident
- Categorized incidents for further analysis of the problem process
- Registered problem record
- Feedback to the Change Management process for incidents linked to a change
- Information and statistics about incidents
Measurement
This is how the Incident Management process can be measured:
- Average time to resolve incidents
- Average time taken by external groupings to provide a solution
- Time between incidents in the same service, system or component
- Number of open incidents
- Average time taken per incident
- Number of and percentage of the total that
- are closed on initial diagnosis
- are classified as major incidents
- are incorrectly escalated
- are incorrectly categorized
- are managed within the agreed time and service level
Challenges
One of the most difficult challenges in relation to Incident Management is keeping the process free from other issues that are not unexpected disturbances in the IT environment. Clear guidelines are required for what is an incident, and continuous follow-up of the staff members who register incidents. It is not unusual for incidents with a low priority to be left for weeks or even months at the bottom of somebody’s pile of issues. One way to counteract this is to terminate the incident record and instead register a problem record. The issue will then be placed in the overall priority for Continual Service Improvement. If the error remains in the IT environment, future issues will be linked to the problem record registered and the priority will be raised.
It is important for the Incident Management process that the documentation of known errors in the Release Management process functions. Otherwise the IT organization risks having incidents registered for existing and already known errors.
In addition, the following elements need particular attention when implementing the process:
- The ability to detect incidents as early as possible
- Getting all administrators working in the process to follow the procedures and document all incidents which arise
- Access to information that is needed in order to rapidly resolve incidents.
- Access to knowledge and documentation regarding the IT environment
- Link to the business and its requirements for prioritization
